Association Rule Mining merupakan bagian dari Frequent Pattern Mining. Frequent Pattern Mining merupakan salah satu task data mining yang sangat penting. Kenapa? Task ini mencari hubungan/relasi, assosiasi, dan korelasi dalam data. Pengetahuan yang dihasilkan juga sangat berguna untuk klasifikasi, clustering, dan task data mining yang lain. Selain Association Rule Mining, masih ada Sequential Pattern, dan Structured Pattern yang termasuk dalam Frequent Pattern Mining. Association Rule Mining dapat juga disebut Frequent Itemset Mining karena pola yang dihasilkan adalah pola item yang sering muncul bersamaan dalam sebuah database.
Contoh klasik yang sering digunakan untuk menjelaskan Association Rule Mining adalah market basket analisis. Pada market basket analisis, kita menganalisa kebiasaan customer dalam membeli barang. Misalkan terdapat data transaksi seperti ini.
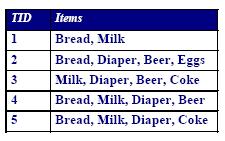
Contoh pengetahuan yang dapat diperoleh dari data di atas adalah
{Beer} –> {Diaper}
artinya orang yang beli beer biasanya beli diaper juga. Lebih jauh, association rule menjelaskan hubungan korelasi antar item dengan lebih jelas, tidak hanya korelasi kuat atau korelasi lemah saja. Hal ini karena adanya beberapa metrik yang digunakan untuk evaluasi rule.
Term-term berikutnya akan membahas lebih lanjut tentang association rule mining termasuk juga teknik yang biasa digunakan.
Mei 10, 2006
Association Rule Mining
Posted by Philips Kokoh Prasetyo under Association Analysis, Term[27] Comments

Mei 18, 2006 at 12:43 am
[…] Ketiga istilah ini sangat penting dalam Association Rule mining. Seperti yang sudah pernah disebutkan sebelumnya bahwa Association Rule Mining disebut juga Frequent Itemset Mining, karena itu Itemset merupakan fokus utama mining. Itemset merupakan himpunan kelompok item. Itemset dengan jumlah item k disebut k-Itemset. Jika menggunakan contoh transaksi pada post Association Rule Mining, {Milk, Bread, Diaper} merupakan salah satu Itemsetnya. Association Rule dinyatakan dalam bentuk X => Y, di mana X dan Y merupakan Itemset. Contohnya : {Milk, Diaper} => {Beer}. Support (s) dan Confidence (c) merupakan metrik yang digunakan pada Association Rule. Support menunjukkan persentasi jumlah transaksi yang berisi X dan Y. Sedangkan Confidence menunjukkan persentasi banyaknya Y pada transaksi yang mengandung X. Bentuk persamaan matematisnya dapat dituliskan seperti ini: Berikut ini adalah contoh Association Rule : {Milk, Diaper} => {Beer} Support menunjukkan persentasi jumlah transaksi yang mengandung item {Milk, Diaper, Beer}. Confidence menunjukkan persentasi {Beer} yang terdapat pada transaksi yang mengandung item {Milk, Diaper}. Nilai Support digunakan untuk menentukan Frequent Itemset. Itemset yang nilai Support-nya memenuhi parameter threshold minimum support (min_sup) masuk dalam Frequent Itemset. Sedangkan nilai Confidence digunakan dalam menentukan Strong Association Rule. Association Rule yang nilai Confidence-nya memenuhi parameter threshold minimum confidence (min_conf) termasuk dalam Strong Association Rule. […]
Februari 6, 2007 at 2:50 am
Salam kenal bwt kokoh,
Q mahasiswa yg skrg lg belajar tentang Data Warehouse Data Mining. Sy sgt jelas dengan artikel yg anda tulis mengenai salah satu metode data mining. Bisakah sy mendapat materinya? Jika bisa dimana saya dapat menghubungi anda?
Terima kasih
Februari 6, 2007 at 5:04 am
Terima kasih banyak atas komentarnya.
Materi yang ada di blog ini diambil dari beberapa sumber.
Anda bisa kontak saya di email yang tertera di halaman “tentang penulis”
Mei 7, 2007 at 3:28 am
saya mahasiswa yang sangat tertarik dengan data warehouse, dan saat ini saya sedang mengambil skripsi tentang market basket, rencananya saya menggunakan sql server 2005 sebagai tool pengolahan datanya, tool tersebut dapat melakukan beberapa analisis statistik salah satunya market basket. namun pada saat ini saya sedang kesulitan menggunakan tool tersebut karena kurangnya suport materi maupun contoh-contoh khususnya tentang market basket. tolong pencerahannya. salam kenal.
September 27, 2007 at 5:40 am
salam kenal untuk Kokoh,
ingin tanya, apakah anda memiliki paper/artikel tentang ujicoba untuk kaidah assosiasi. Bolehkah saya copy untuk bahan tesis saya.
terima kasih sebelumnya atas perhatiannya.
dian.
September 27, 2007 at 8:18 am
saya seorang mahasiswa akan mengambil skripsi tentang data mining khusunya association rule dengan algoritma apriori. bisakah anda membantu saya
September 1, 2016 at 4:56 am
nana bisa saya minta alamat emailnya, skripsi saya juga mengenai aturan asosiasi menggunkn algoritma apriori,,mau saya terapkan dishowroom
September 29, 2007 at 6:22 am
Dian:
banyak sekali resource yang berkaitan dengan association rule mining. Tambahan informasi, Anda bisa menggunakan term “Frequent Pattern”. Coba search di internet. Jika ingin tahu tentang implementasinya bisa mengunjungi website FIMI.
Nana:
Saya sendiri bukan expert di bidang ini. Anda dapat mencari banyak resource tentang association rule. Area ini cukup populer di data mining. Saya hanya bisa bantu sepanjang pengetahuan saya.
Sekedar saran, Anda dapat bergabung dengan milis indo-dm. https://philips.wordpress.com/2006/01/17/komunitas-data-mining-indonesia/
November 8, 2007 at 4:48 pm
saya sedang menempuh skripsi berkaitan tentang market basket analysis. mohon maaf bisakah saya mendapatkan artikel yang berkaitan dengan topik bahasan skripsi saya. kalo bisa bagaimana caranya?
November 9, 2007 at 7:59 am
Mas Iswoyo, banyak sekali resource berkaitan dengan market basket analysis. Permasalahan tersebut berkaitan dengan frequent pattern mining. Coba googling, Anda pasti mendapatkan banyak resource.
Tips pencarian resource dapat dibaca di: https://philips.wordpress.com/2007/05/28/tips-pencarian-resource-di-internet/
Semoga membantu.
Maret 3, 2008 at 1:17 pm
ada nggak ya contoh implementasi algoritma apriori yang pake bahasa PHP? makasih mas..
Maret 3, 2008 at 1:30 pm
@Ogle:
saya tidak tahu, mungkin anda bisa coba search di Google.
April 16, 2008 at 8:00 am
kebetulan Tugas akhir saya tentang Association rules, tetapi yg saya cari untuk yang anomali. dari jurnal yang saya dapatkan metode yg dipake adalah apriori, tetapi dilakukan modifikasi di bagian support countingnya. saya masi bingung mengenai perolehan candidat itemsetnya, karena untuk kasus anomali pada umumnya infrequent, sedangkan untuk metoda yg digunakan yaitu apriori, hanya akan mengambil item yang frequent. bahan yang saya dapat sangat minim sekali. apa bapak dapat memberikan bahan lain yang sekiranya berkaitan dengan TA saya tersebut, saya juga mengharap komentar dan penjelasan dari anda. trimakasih…
April 17, 2008 at 4:00 am
Ide menarik. Saya sendiri tidak pernah tahu tentang hal tersebut. Coba Googling, mungkin ada riset-riset frequent pattern dengan anomaly detection yang terkait.
April 18, 2008 at 5:59 am
saya kebetulan juga dapat jurnal dr pembimbing saya…,pak Arif Bijaksana. banyak hal yg masih kurang saya mengerti, makanya saya berusaha mencari informasi dan sumber2 yang terkait,tp kadang berdasar dari informasi tersebut masi kurang jelas dan kadang makin kompleks jadinya bingung. trimakasih pendapatnya.
April 21, 2008 at 5:46 am
Wah, kebetulan ini juga TA saya. Tapi ada bagian yang saya bingung
[quote]
Task ini mencari hubungan/relasi, assosiasi, dan korelasi dalam data
[/quote]
Maksudnya Relasi itu yang seperti apa? Assosiasi itu yang seperti apa? dan Korelasi itu yang seperti apa ya?
Bentuk representasinya seperti apa ya?
Makasih atas bantuannya ^__^
Juli 4, 2008 at 2:38 am
salam kenal buat mas philips
kebetulan nemu blogs ini pas lagi searching data buat tugas data mining..
mungkin mas philips bisa bantu, kira2x dimana saya bisa mendapat data transaksi penjualan untuk tugas association rule..
terima kasih sebelumnya atas bantuannya..
Agustus 4, 2008 at 9:35 am
Salam kenal buat Pak Philips
Saya sedang membutuhkan bahan tentang association rule dan data mining. Pak Philips punya tidak journal tentang Association Rule dan Data Mining? Saya sudah cari juga, tetapi saya masih bingung mana yg bagus karena pada umumnya ditulis pake bhs inggris. Saya baru aja mempelajari tentang Data Mining.. dan bhs.inggris sy tidak begitu bagus.. harap maklum..
Terima Kasih Pak atas perhatiannya. Saya sangat mengharapkan bantuan dari Pak Philips.
Sekali lagi makasih sebelumnya.
Salam,
dianws
September 24, 2008 at 12:46 am
mau nanya pak.
gmana cara mencari assosiasi untuk item yang kita tentukan.
misalnya: assosiasi yg ddapatkan:
x–>y
w z –>y
a b c –>y
jadi yg dsebelah kanan itu kita tentukan (tidak semua aturan asosiasi dtampilkan).
ada software yg sperti ini tidak?
Desember 4, 2008 at 7:35 am
Saya sedang menyusun Tugas Akhir, dan saya tertarik dengan Classification Based on Association (CBA) pada data mining. Saya menggunakan SQL Server dan C#.
Mohon Bantuannya.
Terima Kasih.
Februari 21, 2009 at 12:13 pm
saya juga lagi tugas akhir nih kira-kira bisa bantu nga tentang Konsep Data Mining atau mungkin ada Forum Khusus untuk Mining, makasih
Juni 29, 2009 at 3:27 pm
salam knl bank,,
sy mahasiswa stmik dp mks,, sy lg buwat mklh ttg datamining,,, mslahnya sy bingnug ambl materinya dimn??? buku yang bagusx apa sich???
Desember 28, 2009 at 5:58 am
mu nanya neh ttg hasil dari association rules,,,aq kan lagi skripsi neh ttg association rule…kira2 hasil/result dari AR tuh bisa dibuat analisa barang yang mengalami pningktan dan penurunan gak dalam transaksi penjualan : misal:
awal bulan :
kopi,gula……maka….susu…..supp 25% conf 66%
tengah bulan :
gula,biskuit…….maka….susu….supp 28% conf 71%
akhir bulan :
teh,gula…..maka….susu….supp 30% conf 80%
kemudian diambil analisis bahwa susu mengalami kenaikkan ataw peningkatan dari awal bulan dg conf 66 %,,tengah bulan dg conf 71% dan pada akhir bulan dg conf 80%.
bisakah diambil kesimpilan seperti itu,,,dasar teoriY dari mana???
terimakasih…bls secepatY y!!!
November 6, 2010 at 7:18 am
saya lagi tugas akhir tentang clusterung menggunakan algoritma CFWS,nah sebelum saya mulai proses algoritma tersebut saya harus gunain assosiation rule mining dngan minimum support,,saya masih rada bingung gimana nentuin nilai min.support terhadap document..bisa tolong bantu saya menjelaskan lebih detailnya ga?
November 6, 2010 at 8:57 am
@Mauliza: secara teori tidak ada aturan pasti dalam menentukan minimum support. Biasanya penentuan ini dilakukan berdasarkan hasil eksperimen.
November 7, 2010 at 10:55 pm
kalo apriori,apa itu cara utk membantu dalam menentukan minimum support? misal ada 1500 data set,ga mungkin kan kita nentuin satu persatu minimum support nya, apakah apriori it alternatif nya atau ada alternatif lain ga?
terima kasih sebelumnya,, 🙂
November 8, 2010 at 12:44 pm
Penentuan minimum support ini tergantung dari problem dan goal yang akan dicapai. Lakukan beberapa experimen, kemudian analisa hasilnya berdasarkan tujuan yg ingin dicapai. Dari situ biasanya akan terlihat polanya.
Mungkin ada beberapa teknik khusus dalam menentukan parameter ini pada domain-domain tertentu. Anda bisa mencari paper-paper yang terkait.