Masalah utama pencarian Frequent Itemset adalah banyaknya jumlah kombinasi itemset yang harus diperiksa apakah memenuhi minimum support atau tidak. Salah satu cara untuk mengatasinya adalah dengan mengurangi jumlah kandidat itemset yang harus diperiksa.
Apriori adalah salah satu pendekatan yang sering digunakan pada Frequent Itemset Mining. Prinsip Apriori adalah jika sebuah itemset infrequent, maka itemset yang infrequent tidak perlu lagi diexplore supersetnya sehingga jumlah kandidat yang harus diperiksa menjadi berkurang.
Kira-kira ilustrasinya seperti ini:
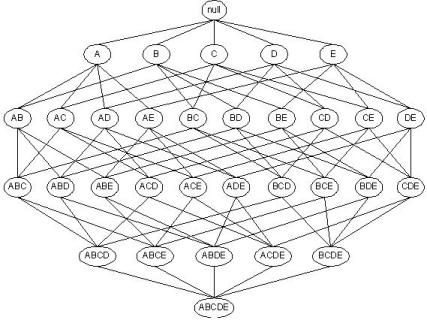
Pada gambar di atas, pencarian Frequent Itemset dilakukan tanpa menggunakan prinsip Apriori. Dengan menggunakan prinsip Apriori, pencarian Frequent Itemset akan menjadi seperti di bawah ini:
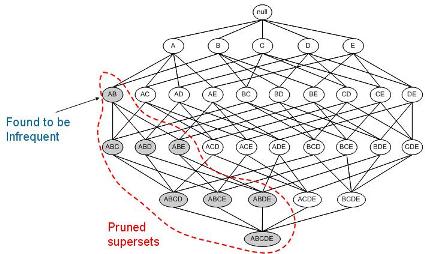
Dapat dilihat bahwa dengan menggunakan Apriori, jumlah kandidat yang harus diperiksa cukup banyak berkurang. Apriori sendiri terus dikembangkan untuk meningkatkan efisiensi dan efektivitasnya. Salah satunya adalah dengan memanfaatkan Hash Tree untuk perhitungan support yang efisien (mengurangi Database scan yang berulang-ulang).
Referensi :
1. Agrawal and R. Srikant. Fast algorithms for mining association rules. VLDB’94.
2. Mannila, H. Toivonen, and A. I. Verkamo. Efficient algorithms for discovering association rules. KDD’94.
3. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association rules in large databases. VLDB’95.

Juli 3, 2006 at 3:04 pm
[…] Secara umum, terdapat dua tahap dalam melakukan Association Rule Mining yaitu Frequent Itemset Candidate Generation dan Rule Generation. Pada tahap Frequent Itemset Candidate Generation terdapat beberapa kendala yang harus dihadapi untuk memperoleh Frequent Itemset seperti banyaknya jumlah kandidat yang memenuhi minimum support, dan proses perhitungan minimum support dari Frequent Itemset yang harus melakukan scan database berulang-ulang. Pendekatan Apriori sangat membantu dalam mengurangi jumlah kandidat Frequent Itemset. Apakah mungkin candidate generation ini tidak dilakukan? Dengan menggunakan FP-growth, kita dapat melakukan Frequent Itemset Mining tanpa melakukan candidate generation. FP-growth menggunakan struktur data FP-tree. Dengan menggunakan cara ini scan database hanya dilakukan dua kali saja, tidak perlu berulang-ulang. Data akan direpresentasikan dalam bentuk FP-tree. Setelah FP-tree terbentuk, digunakan pendekatan divide and conquer untuk memperoleh Frequent Itemset. FP-tree merupakan struktur data yang baik sekali untuk Frequent Pattern mining. Struktur ini memberikan informasi yang lengkap untuk membentuk Frequent Pattern. Item-item yang tidak frequent (infrequent) sudah tidak ada dalam FP-tree. […]
Agustus 7, 2006 at 3:23 pm
[…] Salah satu penghargaan yang diberikan ACM SIGKDD setiap tahunnya adalah ACM SIGKDD Innovation Award. Penghargaan ini akan diberikan pada konferensi internasional KDD setiap tahunnya (tahun ini, KDD 2006 pada tanggal 20-23 Agustus 2006). Dan, tahun ini yang akan menerima ACM SIGKDD Innovation Award adalah Ramakrishnan Srikant. Ramakrishnan Srikant saat ini merupakan research scientist di Google, sebelumnya IBM Almaden Research Center. Hasil publikasinya yang paling terkenal adalah “Fast Algorithms for Mining Association Rules” bersama Rakesh Agrawal yang memperkenalkan konsep Apriori untuk association rule (memperoleh penghargaan 10-year best paper award tahun 2004). Beliau banyak memberikan kontribusi pada permasalahan association rules, sequential pattern, dan privacy-preserving data mining. Banyak orang yang menganggap bahwa data mining dan privacy saling bertolak belakang, dan satu-satunya cara untuk melindungi privacy adalah dengan membatasi penggunaan data mining. Ramakrishnan Srikant dengan cerdik mengatasi asumsi ini dengan mengembangkan teknik privacy-preserving data mining yang bekerja dengan membedakan antara data pada level privacy (data individual) dengan data pada level yang lebih tinggi yang digunakan untuk mining. Beliau pernah menerima outstanding innovation award (IBM), 2 outstanding technical achievement award (IBM), IBM master inventor tahun 1999, dan ACM Grace Murray Hopper Award tahun 2002 sebagai outstanding young computer professional. Beliau juga terlibat sangat aktif pada beberapa konferensi internasional. Pernah menjadi program co-chair KDD 2001 dan PAKDD 2004, vice chair WWW 2006 dan ICDM 2004, dan deputy chair WWW 2004, tutorials chair KDD 2003, dan industrial track co-chair PAKDD 2003. […]
Maret 4, 2008 at 1:20 pm
numpang nanya nih mas/pak, ada nggak contoh implementasi algoritma apriori ini khususnya yang pake bahasa PHP. di FIMI yang banyak pake C++, trus trang saya kesulitan memahami yang pake C++, belum pernah pake C++ soale!! trimakasih atas jawabanya.
Maret 4, 2008 at 2:09 pm
@Ogle:
Sebaiknya anda ikuti algoritma apriori ini dari text book data mining, penjelasan dari text book adalah penjelasan yang paling dasar. Dan mungkin implementasinya tidak secepat yang ada di FIMI.
Anyway, FIMI adalah repository yang awalnya merupakan kompetisi implementasi frequent pattern mining. Implementasi mungkin agak rumit karena memang dirancang khusus agar prosesnya cepat.
Saya tidak tahu apakah ada implementasi (source code) dalam php.
Maret 14, 2008 at 6:21 pm
Mas Philips, saya sedang melakukan penelitian untuk tesis, mempergunakan program Apriori. Ada satu hal yang masih menjadi ganjalan yaitu bagaimana menentukan nilai minimum support dan confidence yang akan dijadikan patokan. Bisa saja saya mengatakan min support yg dipergunakan adalah 30% sehingga apabila hasil yg didapatkan memenuhi syarat minimum support yaitu minimal 30% maka hasil tersebut dapat dipergunakan. Tapi sampai sekarang saya belum mendapatkan landasan teori bagaimana cara bisa menentukan suatu nilai tertentu sebagai nilai untuk minimum support kecuali asumsi.
Maret 15, 2008 at 9:12 am
@Alwis Nazir:
Pertanyaan menarik,
sampai sekarang belum ada aturan umum dalam menentukan minimum support. Penentuan minimum support umumnya berdasarkan aplikasi atau hasil eksperimen.
Sebenarnya justru yang lebih penting bukan supportnya, namun pattern yang diperoleh. Apakah pattern tersebut interesting, berguna atau tidak.
Mei 8, 2008 at 5:22 am
dari suaru frequent 2 item set dihasilkan berapa aturan..??
misal AB frequent
maka dihasilkan A=>B atau A=>B dan B=>A…??
karena A=>B dan B=> memiliki support yang sama dan conffident yang beda
Mei 8, 2008 at 8:04 am
pak philips….
bapak bisa share data transaksi di swalayan punya bapak ga..???
kalau ada bisa minta tolong send ke mail saya….
thx randolf_silaen@yahoo.co.id
Mei 8, 2008 at 12:13 pm
@randolf:
A=>B dan B=>A merupakan candidate rules dari frequent item tersebut. Jelas, masih tetap harus dilihat lagi apakah rule tersebut memenuhi minimum confidence.
PS: Maaf, saya tidak punya swalayan
April 22, 2009 at 7:38 pm
Pak philips, saya kurang setuju dengan pendapat anda mengenai minimum support. Support ditentukan oleh domain expert dari data yang sedang di analisis, bukan experiment atau aplikasi semata.
Penentuan support sangat penting untuk mereduksi jumlah pattern yang diperoleh. Support yang terlalu kecil akan menyebabkan pattern yang didapat sangat banyak sehingga pencarian pattern yg menarik akan menjadi sulit atau bahkan terlewat.
Support yang terlalu besar bisa berakibat pattern yang muncul hanya pattern biasa saja ( seperti komputer dengan stabilizer pada market basket dimana umumnya orang sudah tau pattern seperti ini tanpa harus melakukan analisis asosiasi )
ini bukan teori, tapi praktik dilapangan 🙂
April 23, 2009 at 1:39 am
@anonim:
Saya sangat setuju bahwa domain expert punya kapabilitas untuk menentukan minimum support yang paling sesuai pada suatu permasalahan.
Namun, tidak jarang juga data miner memperoleh data yang tidak mereka kenal. Mungkin karena alasan privacy issue atau karena domainnya terlalu luas.
Pada kasus semacam ini, proses penentuan parameter secara otomatis sangat diperlukan.
perkenalkan diri dong. 😉
Juli 6, 2009 at 2:25 pm
saya mo tanya ni dengan bapak2 disana
bagaimana qta menentukan minimum support dan minimum confidence (apriori)
dan support count pada (pattern growth). misal bapak memasukkan 80 % dan 70%, kenapa harus itu, dasarnya apa?
banyak literatur yang saya baca mengatakan bahwa min support/confidence dan support count adalah didefinisikan sebelumnya
bagaimana qta mendefinisikan?
tq b4
Agustus 8, 2009 at 2:41 am
apk sy bs minta script bahasa php untuk metode association rulenya…yang berhubungan dengan persediaan barang.jika ada penambahan produk baru untuk inputannya itu gimana rulenya…dan apk rulenya jg berubah…
karena ini nyangkut skripsi sy..bisa dikirim ke email saya seminull@yahoo.com.
Januari 22, 2011 at 5:08 am
Salam kenal Pak..
apa Bapak punya skrip apriori ato association rule dalam php ato java?
jika ada tolong kirim k email saya:
doni.juliari@yahoo.com
trims
April 10, 2011 at 1:37 pm
pak apa saya bisa minta script apriori atau association rule dalam php ya?
tolong bantu saya pak, krn ini menyangkut skripsi saya, saya bingung bgt, mohon bantuannya.
tolong dikirimkan ke email saya : haqnee_lho@yahoo.com
April 10, 2011 at 2:24 pm
Maaf, saya tidak punya scriptnya. Algoritma ini sangat umum sekali, anda bisa memperoleh banyak referensi code di internet.
November 13, 2011 at 3:39 pm
salam kenal mas philip
maaf mas, saya mau tanya, ilustrasi frequent itemset apriori itu diambil dari refrensi mana?
terimakasih banyak
November 14, 2011 at 1:25 pm
Banyak sekali ilustrasi frequent itemset mining.
Ini salah satu topik dasar data mining.
Coba google frequent pattern mining, resourcenya luar biasa banyak.
Good luck.
November 15, 2011 at 3:03 pm
pak phillips tidak punya file atau dokumennya?kalau boleh, saya minta sebagai tinjauan pustaka
email saya : sdewanoto@gmail.com
terimakasih
November 15, 2011 at 3:30 pm
terutama pada gambar di postingan pak phillip ini, tahap pencarian frequent itemset tanpa pendekatan apriori dan menggunakan apriori
karena saya mencari di setiap jurnal tidak ada
mohon bantuannya pak phillips
terimakasih banyak
November 16, 2011 at 1:42 pm
@surojo: gambar ini diambil dari bukunya Tan, Steinbach, Kumar. Judulnya introduction to data mining.
Klik untuk mengakses chap6_basic_association_analysis.pdf
Februari 4, 2014 at 9:34 pm
Mas mau tanya apa ya perbedaan dari Frequent Itemset Mining dan Sequential Pattern Mining, koq sy masih bingung yaa.
Terimakasih